Medical Knowledge Corpus Dataset (for fine-tuning Medical LLMs)
May 1, 2024
05/2024 – 12/2024 | Hyper-scale AI Ecosystem Expansion Project, NIA
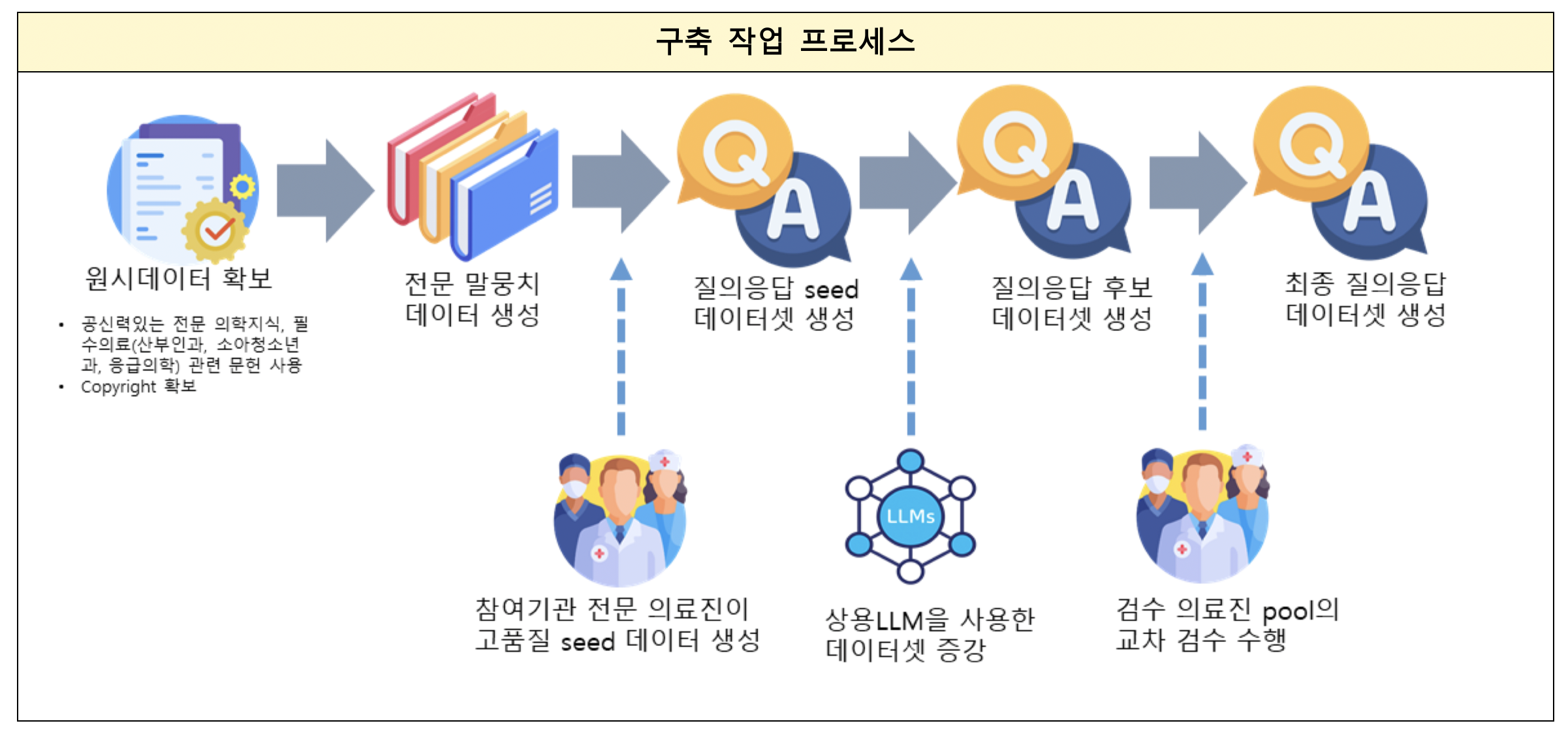
- Constructed and released a high-quality bilingual (Korean-English) medical corpus of 200 million tokens, focusing on professional medical knowledge and essential medical domains (obstetrics & gynecology, pediatrics, emergency medicine)
- Developed two lightweight, domain-specific medical AI models based on large language models using Q&A data authored and reviewed by medical experts
- The curated dataset is intended for fine-tuning medical AI models, aiming to enhance natural language processing performance in the medical domain
- Applicable to various use cases such as clinical decision support, education, and research, laying the groundwork to strengthen Korea’s competitiveness in medical AI
